📊 Full opportunity report: DojoClaw: The Engine Behind the Fleet on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
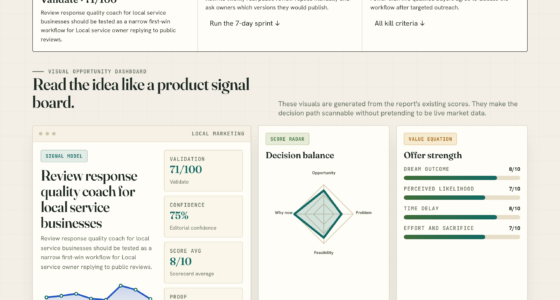
DojoClaw is an AI engine that automates content production for a large network of over 450 websites, using owned hardware and a provider-agnostic approach. This shift aims to improve margins and scalability for digital publishers.
DojoClaw, an AI-powered content engine, now supports more than 450 magazine-style websites, marking a significant shift in how digital publishers scale content production without proportional increases in human labor.
The system, developed by a publisher aiming to reduce costs and increase scalability, transforms raw topics and search queries into fully formatted, monetized pages. Unlike traditional models that rely heavily on cloud API inference, DojoClaw primarily uses owned Apple Silicon hardware to run open-weight AI models locally, drastically reducing variable costs associated with cloud inference. This hardware-based approach shifts the economics from a linear cost increase with output to a fixed-cost model, enabling high-volume production at lower margins over time. The engine is designed to be provider-agnostic, allowing seamless switching between models and vendors, which offers negotiating leverage and reduces dependency on any single platform. The system emphasizes that the value lies not in AI content generation itself but in the surrounding editorial decisions, topic selection, and system design that produce defensible, high-quality pages.DojoClaw — the engine behind the fleet
One operator. 450+ magazine-style sites. Not scaled by hiring — scaled by building an engine, and a template every other product inherits.
Local inference meter — where the work runs
Target: 70–90% of inference local. Rented cloud is a cost line that climbs with every page you publish. Owned compute is paid once, then ridden — so the marginal cost of the next page falls toward the price of electricity. Cloud frontier models are routed in only for the work that genuinely needs them.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. Portions of the products described generate content via automated AI pipelines and may contain errors — verify independently before relying on any of it for a decision. As an Amazon Associate the author earns from qualifying purchases; pages across the fleet may contain affiliate links. Product and company names are trademarks of their respective owners; mention does not imply endorsement.
Economic Advantages of Local AI Infrastructure
By shifting most AI inference from cloud services to owned hardware, DojoClaw significantly reduces ongoing costs, enabling publishers to scale content production profitably. This approach offers a competitive edge by lowering marginal costs and increasing operational leverage, which is crucial for high-volume digital media operations aiming for sustainable growth and margin preservation.

Psitek M4 M5 Mac mini Stand, Silver Holder for Mac mini 2024-2026 with Ventilation Heat Dissipation Cooling, Desk Mount Accessories with Anti-Slip Silicone and Dust-Proof Nets
Upgraded Design with Enhanced Protection: The top and bottom of the stand feature anti-slip and scratch-resistant silicone pads,...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Scaling Challenges in AI Content Production
Traditional AI content operations often rely on cloud inference, incurring variable costs that grow linearly with output. As publishers expand, these costs can become prohibitive, limiting scalability. DojoClaw's innovation lies in using local, owned hardware to mitigate this issue, a move that aligns with broader industry efforts to control costs and avoid vendor lock-in. The system's architecture emphasizes flexibility, provider independence, and a focus on defensible content quality over raw generation volume.
"The engine is provider-agnostic, allowing seamless switching between models and vendors, which offers negotiating leverage and reduces dependency."
— Thorsten Meyer, source author

AI Systems Performance Engineering: Optimizing Model Training and Inference Workloads with GPUs, CUDA, and PyTorch
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Remaining Questions About Long-Term Scalability
It is not yet clear how the system will perform at even larger scales or how it will adapt to rapid changes in AI model availability and pricing. The economic benefits of owned hardware depend on long-term hardware costs and maintenance, which remain uncertain.

Local LLM Inference Optimization: A Comprehensive Guide to Quantization, Hardware Acceleration, and Efficient Private AI Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in DojoClaw Deployment and Optimization
The company plans to expand the fleet of owned hardware, refine model routing strategies, and further develop the system's ability to switch models dynamically. Monitoring performance, cost savings, and content quality will be key milestones in the coming months.

Agentic Artificial Intelligence: Harnessing AI Agents to Reinvent Business, Work and Life
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
How does DojoClaw reduce content production costs?
By using owned Apple Silicon hardware to run AI models locally, DojoClaw minimizes reliance on expensive cloud inference, lowering marginal costs as output volume increases.
What makes DojoClaw provider-agnostic?
The engine is designed to work with multiple AI models and vendors, allowing seamless switching based on cost, quality, or availability, thus avoiding vendor lock-in.
Can DojoClaw produce high-quality, defensible content?
Yes, the system focuses on editorial oversight, topic selection, and content formatting to produce pages that are both high-quality and resistant to being dismissed as low-value AI spam.
What are the main risks or uncertainties?
Long-term hardware costs, hardware maintenance, and the ability to scale effectively without degradation of quality or unforeseen technical issues remain uncertain.
Source: ThorstenMeyerAI.com